I briefly touched on photogrammetry in a previous post. I find this method to be particularly interesting as it feels like the possibilities are endless. The whole world is basically an open-source asset library, in theory, anything can be digitized and used however you please. The method involves photographing a subject from many angles, running it through some software, and getting a fully realized 3D model out of the other side.
My first contact with this technique was using a now-defunct app called display.land. Essentially what this service allowed you to do was create a photogrammetry asset through point clouds generating using video, meaning you didn't have to take several photos and you received live feedback as to what points have been captured successfully.

Display.land
With this service, (I call it a service because the actual software used to be on a server and not existent within the app) I managed t create a very low-quality 3D model of myself. the following media shows the results of these tests.

https://twitter.com/GhostBrush_/status/1276619387420782599
https://twitter.com/GhostBrush_/status/1276586259864002560
I previously touched on the statue base asset I created using photogrammetry (below).
It came to my attention that I didn't really document my workflow on how i came to this conclusion so I set out to create a new one.
It can be hard to pick a good option as some places may greet you with odd looks from strangers wondering why on earth you are walking in circles and photographing the same subject, other locations are simply inaccessible to get the correct kind of shot.
Fortunately, the streets are much less populated due to ahem...
...Current world events...
...ahem...
...So the odd looks are not so much of a problem.
Recently on one of my walks around the city of Liverpool blessed me with this cheeky and completely harmless piece of petty vandalism. (below)
Before I get in trouble I must stress that whoever this rogue statue masker is, it isn't me.

Now in my research, I couldn't find much about Henry Cotton, the man in the statue. I know he was the first Chancellor of the University I attend, and it's hard to say how he would have felt about this. I like to think a man of education would support the use of facemasks in our current time so all I can do is hope he would approve.

here is a picture of him without a mask courtesy of https://artuk.org/
To capture this statue in a 3D sense the first thing you need is a camera and the patience to walk in concentric circles for a bit.
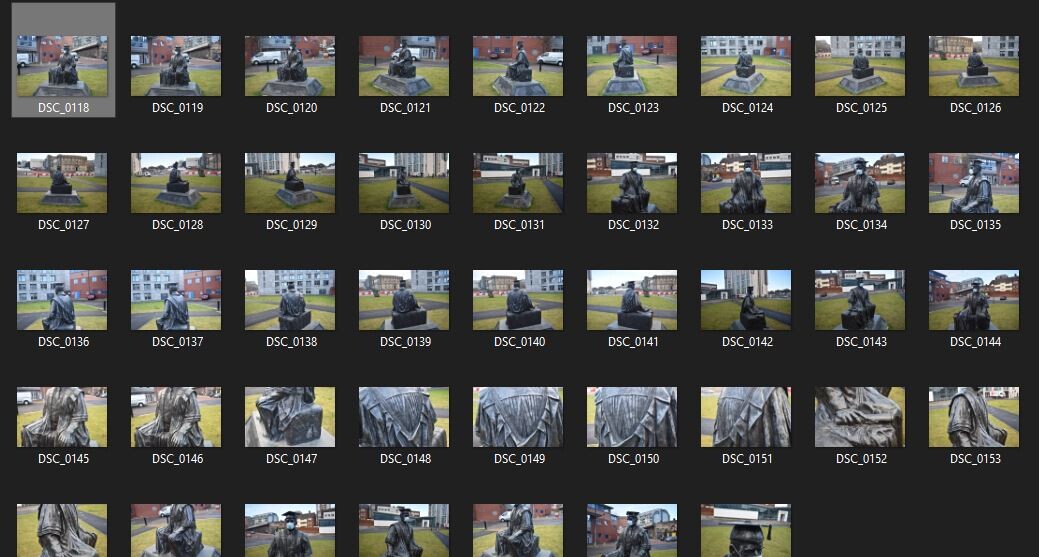
Above shows roughly what you're aiming for, many of these images turned out unusable, thus is the struggle of a photogrammeter. Once you have a nice array of images from all different angles it's time to plug it into your software of choice. I'm using 3DFZephyr for this, however, you can use whatever you like.
First things first you need to generate a Sparse Point Cloud. this is just a loose scattering of duplicate anchor points. Basically, the software finds similarities between the photographs and pins them for further detail extrapolation later.
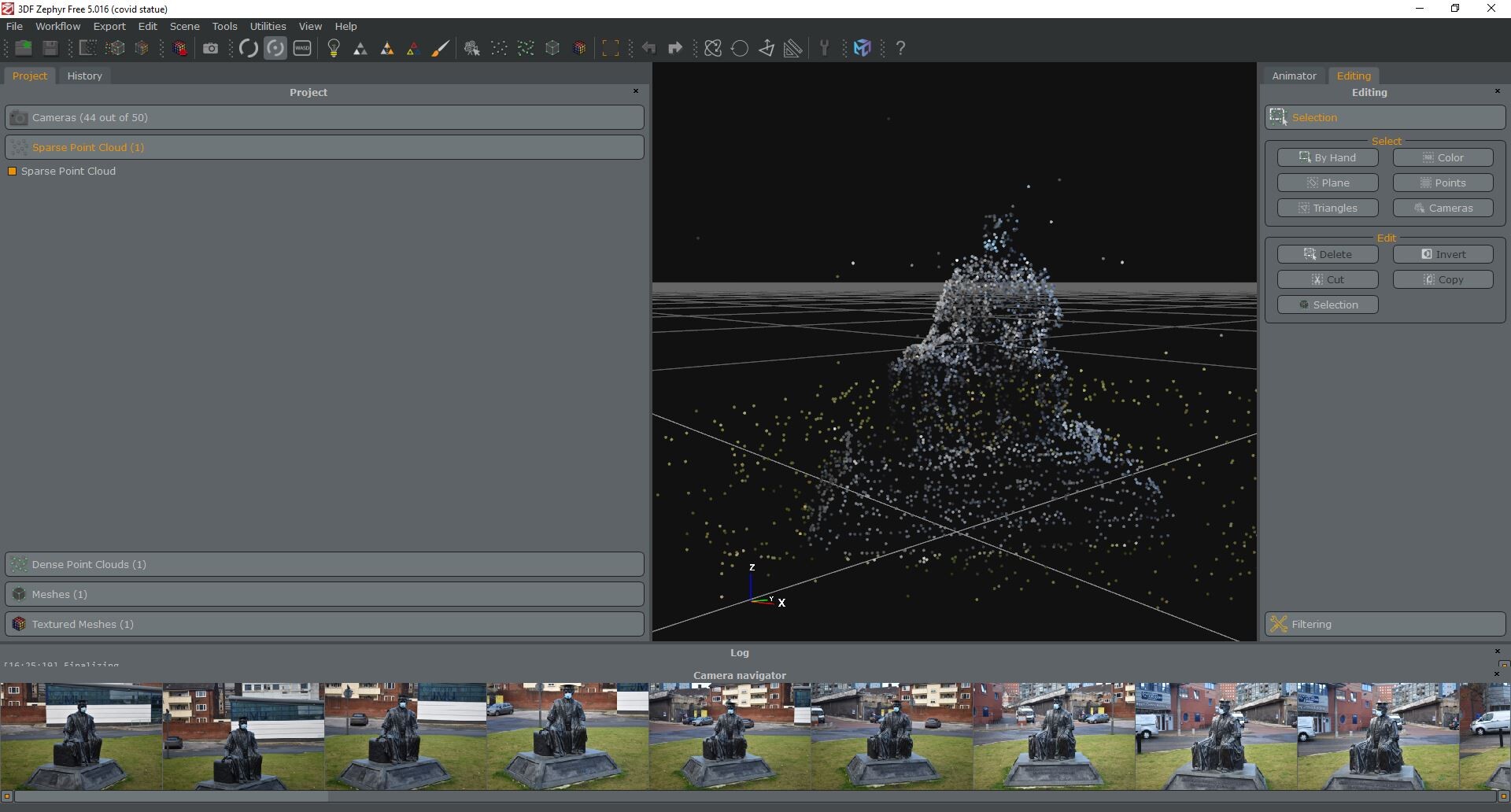
this is actually a much cleaner version than what initially generated, much of the surrounding architecture was captured so I gave them the snip and moved on to the next stage. To achieve, this stage is actually one button press and a lot of waiting and looking at stuff like this:
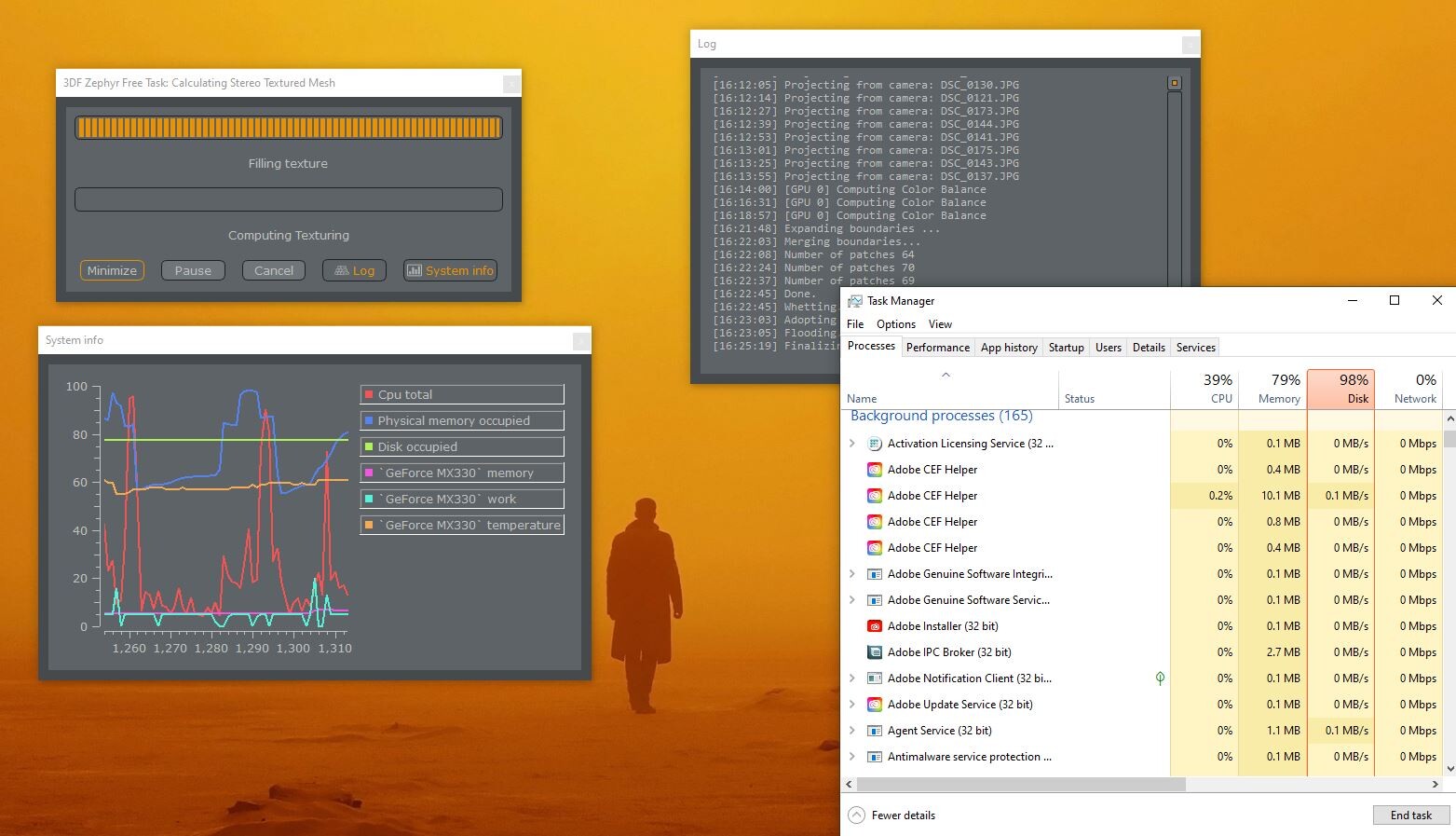
However, this stage is actually doing a couple of stages at once without you needing to see. The first pass is the Dense Point Cloud:

This is basically the process of subdividing the Sparse Cloud and coming to accurate estimations of volume based on the source images. this is basically coloured dots or Voxels and no geometry is yet present. that's where the meshing begins.
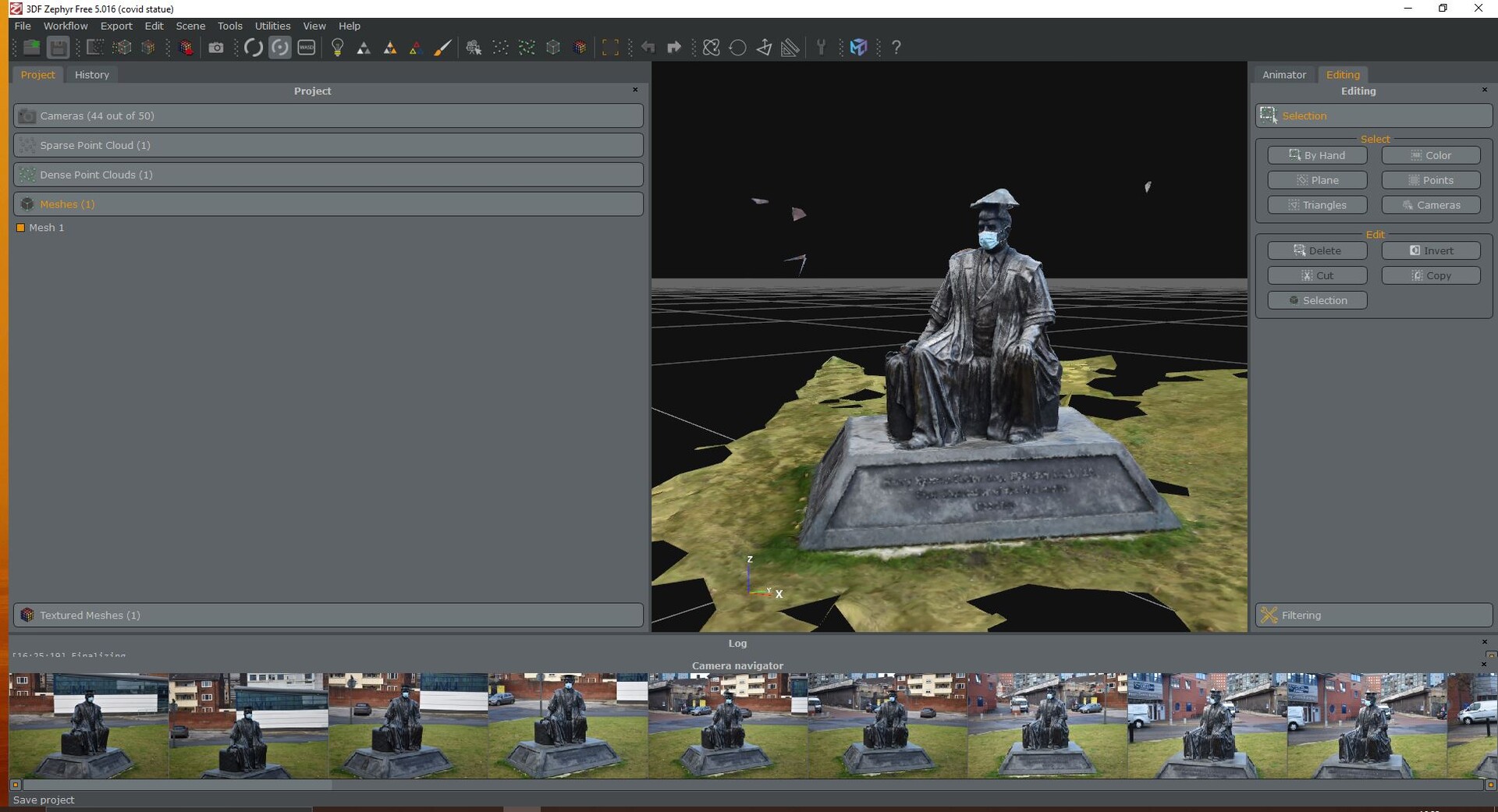
And now we have Geometry! Granted at this point its geometry only a mother could love, but geometry nevertheless. you may start to notice certain hiccups or errors, but this is not the time to worry about that, what is important is that we created fairly accurate volumetric data and turned it into data that a game engine might be able to understand. The next step makes that a reality. we just need to look at a little more of this...
...While the software creates a fully textured mesh from the initial mesh
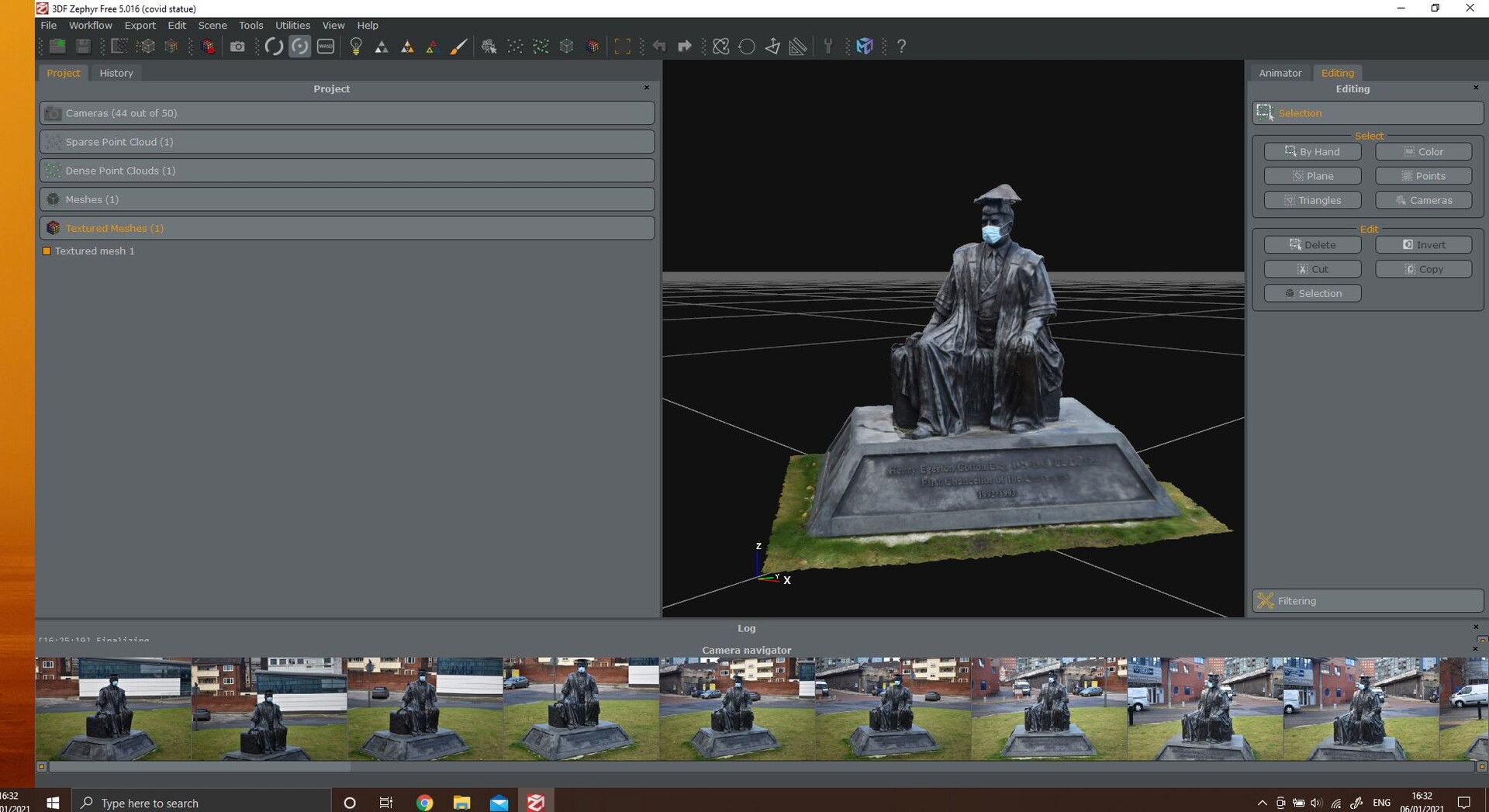
After giving the grass a little trim I've now got a fully textured mesh ready to fix in blender. there's a gleaming issue with the cap that needs sorting out, often you find this sort of things when the subject is taller than you are.

with some cleanup, you have a final model ready to show off to your friends and use however you please! here is a render and an interactive model viewer of the final result.

If you look at the top of the hat it is clear that some repair work has been done, however, I think it is important to ensure these repairs are done in order to sell the idea of the physical counterpart. I've noticed in both my large scale photoscan attempts, that the top is always the part that needs the most work. I suppose a real pro in this field would have some sort of crane or lift to make sure every angle is captured, however, I'm doing this guerilla-style so I don't mind a little cleanup here and there.
Also upon uploading this piece I noticed that I am not the first to use this statue as a photoscan here are examples of other people's attempts.
https://sketchfab.com/3d-models/final-henry-cotton-statue-high-64964d9e69bf4b8fbbc6043c9dc96d60
https://sketchfab.com/3d-models/henry-cotton-statue-af948b38ae924425945b0418c72036bd
These are both really cool and capture the detail in different ways. I suspect the kind of camera used and views selected have an effect as well as differences in weather etc. so there are many avenues to explore in what makes a good scan.
note to self, I must look up other attempts before I do my own, rather than after, as this may have shown me what to watch out for and what works well.
I'm going to end this post with a picture of the statue from better days. here's to hoping we'll see him like this again soon.

References
https://artuk.org/discover/artworks/henry-e-cotton-esq-first-chancellor-of-liverpool-john-moores-university-1992-65543https://en.wikipedia.org/wiki/Henry_Egerton_Cotton
https://sketchfab.com/